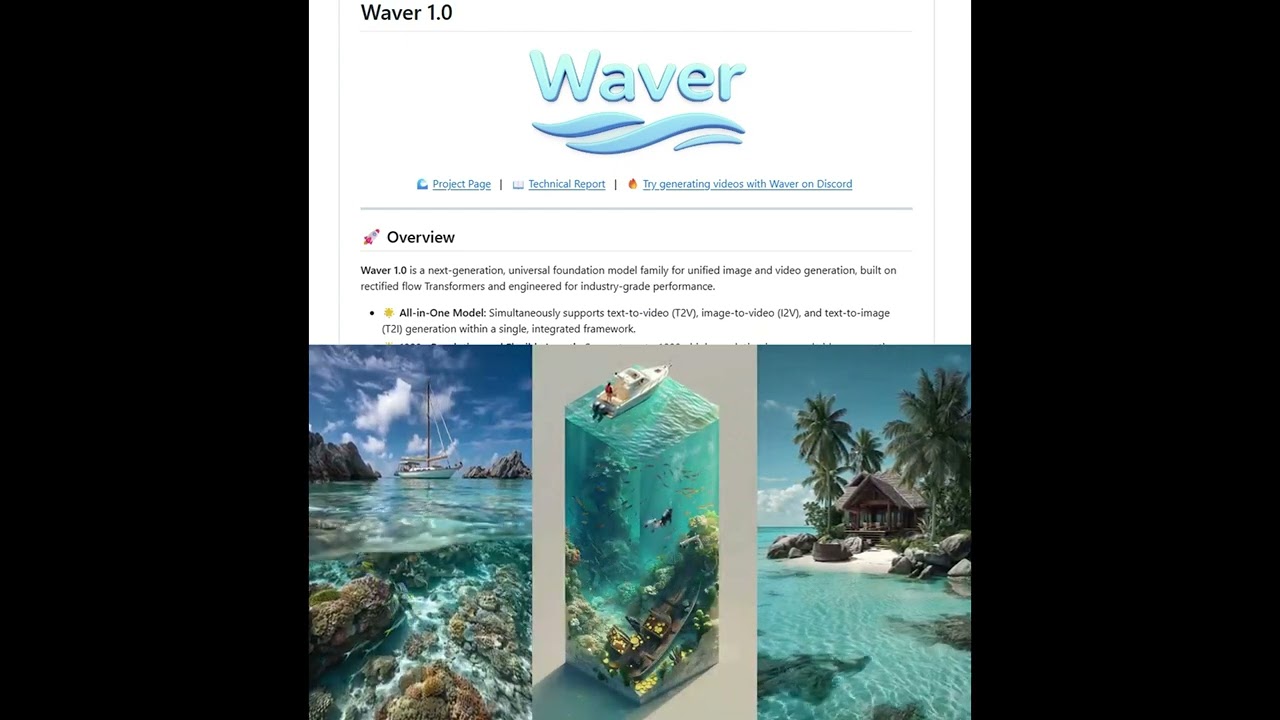
ByteDance has introduced Waver 1.0, a groundbreaking artificial intelligence platform engineered to generate highly realistic images and videos. This innovative system merges cutting-edge techniques to produce rich visual media, enabling seamless transitions and multiple camera perspectives within a single video sequence. The development marks a significant stride in digital content creation, elevating both technical performance and creative potential.
What sets this technology apart is its integration of image and video generation processes into a unified framework. By doing so, it achieves remarkable fluidity and coherence across frames—a challenge that has long constrained AI-driven video synthesis. Positioned alongside some of the industry’s most advanced models, this release boasts capabilities that cater to the increasing demand for dynamic, high-definition content, especially in scenarios requiring complex motion, such as sports and action segments.
Offering broad accessibility, the platform encourages user interaction through an intuitive interface designed for experimentation and feedback. This openness fosters community engagement while enabling a wide range of applications in professional and creative fields alike.
At its core, Waver 1.0 incorporates sophisticated architecture that effectively balances spatial detail with temporal continuity. By employing specialized encoding methods, it ensures videos maintain logical frame sequences without flicker or inconsistencies in motion. The architecture differentiates spatial processing—focusing on textures and composition—from temporal layering, which models frame-to-frame relationships. This dual approach enhances realism and helps maintain seamless motion.
Another defining feature is the system’s ability to automatically orchestrate shifts in perspective within a single video. This multi-angle generation eliminates the need for labor-intensive editing and enables storytellers to present scenes from various viewpoints organically. This capability not only broadens narrative depth but also streamlines production workflows, making complex visual sequences more accessible to creators.
Moreover, the model’s training leveraged meticulously curated datasets and advanced annotation techniques, ensuring the output prioritizes high-quality motion depiction and spatial consistency. These elements culminate in videos that preserve photorealistic fidelity while capturing subtle dynamic details critical to immersive experiences.
One of the significant advancements delivered is the fluid integration of multi-shot storytelling within the same video sequence. Complex scenes featuring character consistency, varied lighting, and smooth spatial transitions are generated natively, without manual stitching. This elevates narrative possibilities by expanding how stories can unfold visually.
The platform’s interactive nature invites users to directly experiment with content creation, providing real-time feedback loops that inform ongoing improvements. This participatory approach broadens versatility, allowing professionals in entertainment, marketing, and education to tailor visual narratives with unmatched precision.
By supporting both text and image inputs for video generation, the system accommodates diverse entry points for creative conception. Whether producing cinematic clips, promotional materials, or instructional media, its adaptable capabilities meet a wide spectrum of demands, pushing the envelope for next-generation visual content production.
This release signals a turning point in how artificial intelligence can transform media workflows. The convergence of image and video synthesis under a single framework not only boosts efficiency but also enhances the scope of creative expression. The ability to generate high-resolution, realistic videos with natural motion dynamics opens new opportunities across industries reliant on visual storytelling.
As content continues to drive engagement in digital platforms, tools that reduce production complexity while delivering cinematic quality will become increasingly essential. The introduction of such advanced technology fosters innovation by granting creators unprecedented control and flexibility in visual composition.
Ultimately, this advancement exemplifies how integrating sophisticated AI models with user-centered platforms can redefine standards for media production, setting a new benchmark for performance and storytelling potential. It offers a glimpse into a future where seamless, multi-perspective visual narratives are not only feasible but accessible to a wider creative community.



